Ohio Speaks
About
Language in Ohio is very diverse. There are several documented dialect regions within the borders of the state as well as social variation within and across those regions. Geographic dialect boundaries come from settlement patterns of European settlers as they moved west across the continent. We can see that today's patterns for pronouncing vowels look a lot like yesterday's patterns for building barns!
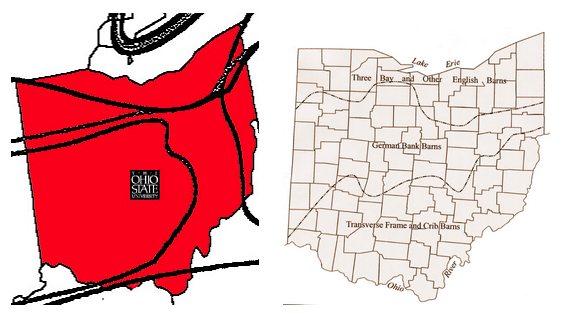
Image adapted from The Atlas of North American English and HeartlandScience.org
How does Ohio speak?
Much of the work that has been done on the speech of Ohio focuses on the sound systems or the different ways people pronounce the same words.
Ohioans aren't the only ones with variable speech, though, and they're not the only ones who come to OSU!
Ohio Speaks is collecting speech from students to learn how people from all these different places pronounce words and how that pronunciation changes during students' time at OSU.
How does OSU speak?
College students may find themselves for the first time in regular interaction with people of different regional, ethnic, racial, religious and socioeconomic backgrounds. As emerging adults, students are also busy embracing, resisting or otherwise positioning themselves with respect to these categories. At OSU, students experience not only social diversity, but linguistic diversity as well. The undergraduate population at OSU comes from 50 states, and from all over the state of Ohio—which is home to many different regional dialects. Such exposure to new varieties is likely to exert influence on student’s linguistic systems—influence which is likely moderated by certain identity factors that students bring with them from their hometown, as well as those that develop on campus.
How does OhioSpeaks work?
Ohio Speaks integrates research and pedagogy by involving undergraduate students every step of the way. Undergrads are our research participants, students, research assistants, fieldworkers and fellow researchers.
The core of our method involves data collection modules in which students create data for use in their courses. These data might be:
- Recordings of speech
- Demographic information
- Information about word use
- Insights into the social world of OSU
OhioSpeaks helps the instructors and students with how to create and analyze the data, then uses the answers found in the data to enhance the insights of the course. Afterwards, students are asked whether they would like to allow our team to keep their data for use in the larger research project. Only data from those who say yes is kept, but everyone in the class gets the benefit of having seen how the research process works!
Our most common form of data is recorded speech. Thanks to recent advances in technology, we are able to automatically automatically segment the recordings at the phoneme level using the Penn Forced Aligner, like this:
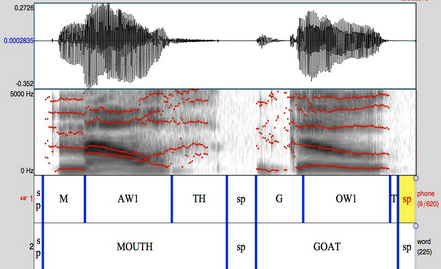
Then we use Praat to automatically extract the formant values, durations and pitch values for each vowel. Integrated with demographic information, these form the raw data we use for our research and for teaching.
Depending on the class, we might:
- Send the raw data back to the students for them to practice statistics on.
- Analyze the class’s data as a whole and explain the patterns to the class.
- Give each student a copy of their own vowel plot, with an explanation of what they show.
After using the whole class’s data to help the student participants learn, we ask for their permission to keep the data for use in our research. Each student can decide to give or withhold their consent individually and only data from those that say yes go into our database.
The modules are tailored to each class in order to meet the specific learning goals for that course, while collecting data that may be analyzed towards achieving overall research goals.
From each student, we also collect demographic data through use of a questionnaire. The questionnaire targets basic demographic information, such as the age, gender, and hometown of speakers, as well as questions specific to OSU.
The data is analyzed and returned to students in a pedagogically useful form within a week.