Outcome:
As part of a multi-site collaboration, linguist Mary
Beckman and computer scientists Eric Fosler-Lussier and
Mikhail Belkin at the Ohio State University
are building computer models of how babies learn the
consonants and vowels of their mother language,
despite the fact that their vocal tracts are too small for them to
acoustically match ambient speech sounds.
One of the first models that we built demonstrated that a mother
"mimicking back" sometimes when she hears babblings that she interprets
as the vowels in "heat" and "hot" is enough to make the baby learn a
mapping not just for those two sounds, but also for other intermediate
sounds, such as the vowel in "hay".
Impact:
In building different computer models, we vary the simulated input
from the baby's own babbling (to reflect effects such as the silencing of
tracheostomy) and also the simulated input from adult speakers (to reflect
differences in the amount of speech that the baby hears).
A better understanding of the role of input can help us develop more
effective policies and programs to aid parents of babies at risk
for language delay.
Background:
It seems obvious that babies learn speech sounds by imitating the speech
they hear. However, because babies' vocal tracts are tiny, the imitation
cannot be a simple pattern match.
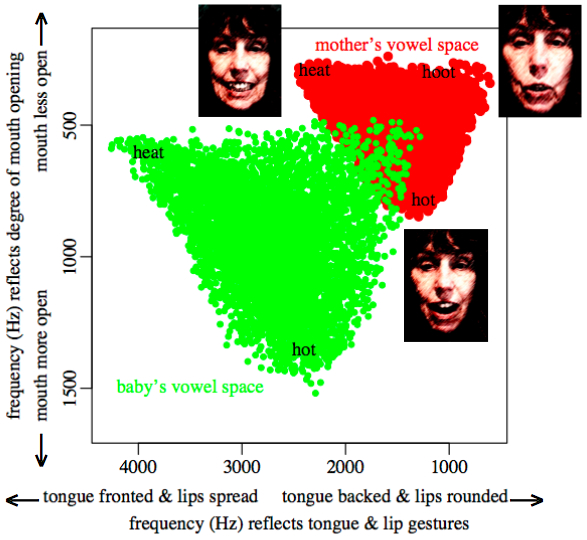
For example, when a mother says the vowels in "heat" and "hot" the
frequencies (in Hz) of the resonances that indicate the different mouth and
tongue gestures for these vowels are completely non-overlapping with the
frequencies that the baby's vocal tract can produce.
And there is "misleading" overlap in the parts of the vowel resonance
space that are shared.
The babbling resonance pattern that the mother interprets as the vowel
in "hoot" juts into the mother's space for her vowel in "hay",
a sound halfway between "heat" and "hot" in terms of degree of mouth opening.
So babies have to learn a complex "mapping" between their mother's speech
and their own babbling.
We are trying to understand this complex learning process by building
mathematical models called manifolds. A manifold describes what our brains
might know about something that is very complex and multi-dimensional by
building a much lower-dimensional "map" of it.
For example, a map of the world is a two-dimensional manifold built to
describe what we need to know to navigate the three-dimensional surface of
our planet.
Our models combined real-world data from children's productions,
real-world data on the speech spoken to children, and
real-world data on adults' perception of the accuracy of children's
productions.
We have already shown that manifolds are a useful way of understanding
some key aspects of early language acquisition, and
we are working with manifolds to try to understand more key aspects.
|